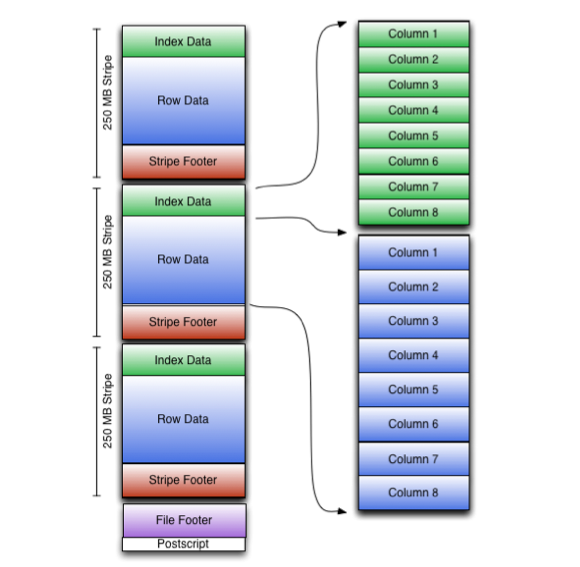
데이터를 Hive 테이블로 가져와 생성하면 Hive Query, Pig, Spark 등을 통해 데이터를 처리할 수 있다. Hive 테이블은 저장되는 위치에 따라 내부 테이블, 외부 테이블 두가지로 나뉜다. 내부 테이블 하이브 데이터 웨어하우스(/hive/warehouse)에 저장되어 Hive가 직접 관리하는 테이블이다. 내부 테이블을 삭제하면 Hive 테이블 metastore 정보와 테이블에 들어있는 모든 데이터가 같이 삭제된다. ORC(Optimized Row Columnar)파일을 통해 최적화 된 저장 방식을 사용할 수 있어 비교적 좋은 성능을 낼 수 있다. # .csv 파일 -> 내부 테이블 생성 예 CREATE TABLE IF NOT EXISTS Names_text( > Column1_name ,..