ETL 설계서 문서화
1~4단계를 거치며 도출된 결과는 ETL 시스템을 위한 상세 구성을 수립하기 위한 문서화 과정이다.
이러한 과정을 완료하기 위해 원천 시스템과 데이터를 사용해야 할 때가 있는데, 이를 위해 원천과 똑같이 복제한 정적 스냅샷인 샌드박스 시스템을 구현할 수 있다.
1단계: 고수준 계획의 도식화
기획 단계에서 정해진 정보들을 통해 매우 간단하게 도식을 그린다.

2단계: ETL 도구 선택
3단계: 기본 전략 수립
ETL 시스템에서 공통적인 컨벤션이나 활동에 필요한 기본 전략을 도출한다.
다음과 같은 것들이 공통 활동으로 여겨진다.
- 각 주요 원천 시스템에서 추출하는 방법
- 추출한 데이터를 스테이지에 보관하는 방법
- 딤멘션과 팩트의 품질을 관리하는 방법
- 디멘션 데이터의 이력을 관리하는 방법
- DW와 ETL 시스템의 가용성 요건 확인
- DW의 각 레코드에 태깅되는 감사 정보 설계
- ETL 스테이지 영역 정리 방법
- …
4단계: 테이블 단위 상세 계획 수립
DW 내의 대멘션/팩트 타깃 테이블에 데이터를 채워넣기 위한 상세 변환 로직을 설계한다.
계획 수립 과정과 함께 데이터 프로파일링을 수행하야 할것이다.

초기 적재 프로세스 개발
ETL 스팩이 만들어지고 나면, 과거 데이터를 한 번에 적재하는 초기 적재 ETL 프로세스 개발을 진행한다.
5단계: 디멘션 테이블 초기 데이터 적재
SCD Type 1 테이블과 같은 가장 단순한 차원에서부터 적재를 시작한다.
성공적으로 적재가 완료 된다면, SCD Type 2와 같은 복잡한 차원의 적재를 시작한다.
테이블에 적재하기 전, 디멘션으로 적절하게 변환하여 스테이징 하는 과정을 거친다. 이 단계에서 모든 데이터는 무조건적으로 검증을 거쳐야 한다.
디멘션으로 변환
- 간단한 데이터 변환
- 다른 원천의 데이터 결합
- 다대일, 일대일 관계 무결성 검증: 스테이징 영역에서 검증을 위해 스노우플레이킹을 사용할 수 있다.
- 대체 키 지정: 스테이징 영역이 DBMS라면 시퀀스를 생성할 수 있다.
변환이 완료된 디멘션을 테이블에 적재할 때 다음과 같은 몇가지 유용한 팁이 있다.
테이블 적재
- 오버헤드 방지를 위해 로깅 중지
- 데이터베이스의 고속 대량 적재 기능 사용
- 인덱싱 속도 향상을 위해 사전에 데이터 정렬
- 테이블의 전체 데이터를 갱신하는 경우, 사전에 테이블 일괄 삭제
6단계: 팩트 테이블 초기 데이터 적재
이는 디멘션 테이블 데이터 적재량 보다 몇천배까지 클 수 있다.
데이터 추출
- DW에 유용한 레코드인지 확인
감사 데이터 및 통계 축적
- DW와 원천 사이 무결성을 상호 검증한 건수 통계 등
팩트로 변환
- null값 변경, 대체 키 매핑, 감사 차원 키 지정, 피벗, 피벗 해제, 파생 지표 계산 등
테이블 적재
- 가장 중요한 이슈인 적재 성능 향상을 위해 적절한 배치 전략 적용
- 다음과 같은 적재 단계를 포험
- 적재하기 전 팩트 테이블과 디멘션 테이블 간 참조 키(참조 무결성)를 비활성화
- 팩트 테이블의 인덱스를 제거 혹은 비활성화
- 고속 적재기술을 이용하여 데이터를 적재
- 팩트 테이블 인덱스를 만들거나 활성화
- 필요하다면 테이블의 파티션을 병합
- 디멘션 테이블의 대체 키 칼럼 값이 유일값인지, 혹은 UNIQUE 인덱스가 있는지 확인
- 팩트 테이블과 디멘션 테이블 간 참조 키를 활성화
변경 데이터 적재 프로세스 개발
변경 데이터의 적재는 데이터의 잦은 갱신을 포함한다.
데이터 갱신 작업은 DW 환경에서 자원 소모가 심한 작업이기 때문에, 이 소모를 최대한 줄여 성능을 개선해야 한다.
7단계: 디멘션 테이블 데이터 갱신
디멘션 증가분에 대한 처리는 앞선 초기 데이터 적재 과정과 유사하다.
디멘션 테이블 추출
- 디멘션 테이블에 적재되어있는 전체 데이터를 추출
- 가능하다면 변경된 열만 추출
신규 혹은 변경된 디멘션 데이터 식별
- 디멘션 테이블 데이터의 원천키와 적재 대상 데이터의 원천키를 비교하여 디멘션 멤버 검색
- 매핑이 되지 않는 데이터는 새로운 디멘션 멤버로 삽입
- 각 컬럼을 비교해야하는 데이터의 경우, 두개의 해싱 컬럼을 사용해 효율적으로 비교할 수 있음
디멘션 속성 변경
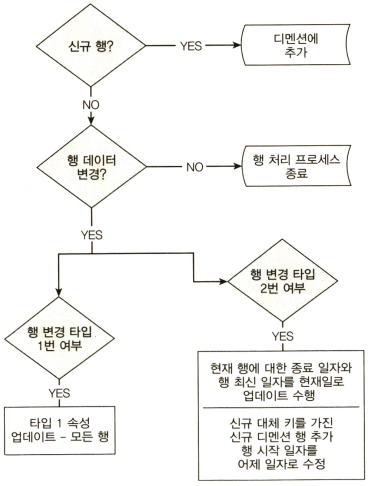
8단계: 팩트 테이블 데이터 갱신
데이터 추출과 품질 지표 산출
- 팩트 테이블에 적재되기 위해 원천 데이터베이스로부터 추출된 데이터를 스테이징 영역에 복사
- 복사와 동시에 데이터의 품질을 확인하며 품질 지표 산출
팩트로 변환
- 초기 적재 파이프라인과 유사하지만, 파이프라인 자동화가 필수적
- 참조 무결성 오류 처리 자동화가 주요 과정
- 참조 무결성 오류 발생 시, 다음과 같은 몇가지 기법을 통해 처리 가능
- 적재 중단: 거의 유용하지 않은 기법
- 에러 발생 열 제거 혹은 기록: 모든 열이 적재되어야 하는 재무 시스템에선 좋지 않은 기법
- 새로운 대체키를 생성하는 더미 디멘션 열을 적재: 해당 열의 상세한 정보를 확보할 때 SCD Type 1 방식으로 더미 디멘션 열을 갱신
- 각 디멘션의 ‘알 수 없음’ 열에 매핑: 여러 팩트 데이터들이 하나의 대체키로 연결되기 때문에 추천하지 않는 기법
지연 도착 데이터 처리
- 뒤늦게 도착하는 팩트 데이터는 해당 팩트가 발생한 시점에 해당하는 디멘션 멤버와 연결되어야 함
- 디멘션 룩업 시 유효 시작 일시와 유효 종료 일시를 조건으로 걸어야 함
팩트 데이터 증분치 적재
- 타깃 테이블이 비거나 인덱스가 없어야 하는 제약 조건 때문에 고속 적재 기능은 일반적으로 사용 불가능
- 전략적인 파티션 분할을 통해 항상 비어있는 파티션으로 데이터가 적재된다면, 너무 많아지는 파티션을 관리하기 위해 주별/월별 파티션으로 병합하는 프로세스를 구현해야 함
주기/누적 스냅샷 팩트 데이터 적재
- 주기적 스냅샷 팩트 테이블은 보통 월 말에 적재하며, 월별 파티셔닝으로 성능 향상 가능
9단계: 집계 테이블과 OLAP 큐브 적재
10단계 ETL 시스템 운영과 자동화
작업 스케줄링
예상 가능한 오류의 자동적이고 적절한 처리
'데이터 엔지니어링 > 빅데이터' 카테고리의 다른 글
| [2. ETL 구축] 2-1. ETL의 서브시스템 (0) | 2024.04.22 |
|---|---|
| [1. 차원 모델링] 1-2. 차원 모델 설계 시 몇가지 팁 (0) | 2024.04.22 |
| [1. 차원 모델링] 1-1. 차원 모델 설계의 4단계 (0) | 2024.04.22 |
| Hadoop YARN (0) | 2022.11.30 |
| Apache Kafka (0) | 2022.06.07 |