Twitter 실시간 처리를 위해 RabbitMQ를 사용할까 하다가 Zookeeper도 설치되어 있을 겸 Kafka를 사용하여 실시간 처리를 진행하려 한다.

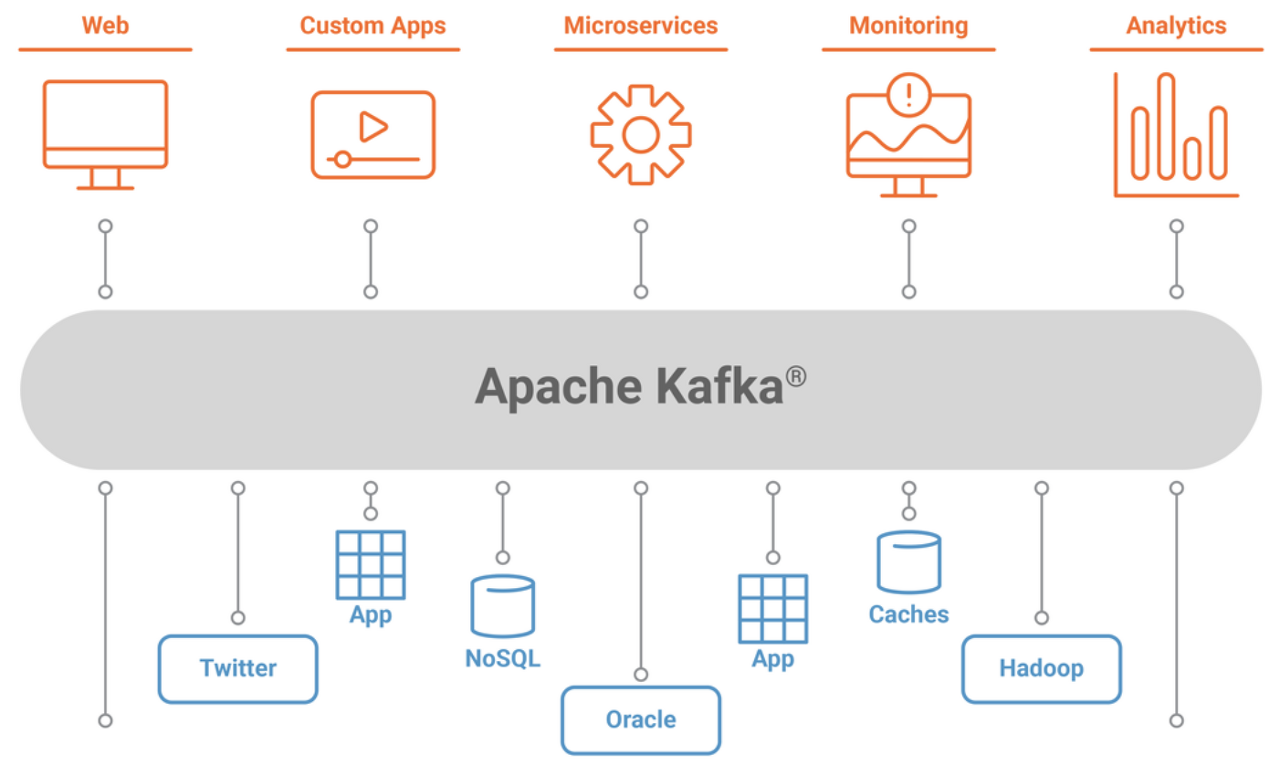
Kafka란?
Apache Kafka는 실시간으로 Record 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산 데이터 스트리밍 플랫폼이다.
하루에 1조4천억 건의 메시지가 생성되어 이를 처리하기 위해 LinkedIn이 개발한 내부 시스템으로 시작 했으며, Pub-Sub 모델의 메시지 큐 구조를 지닌다.
Kafka의 특징
확장성, 높은 처리량, 낮은 지연시간, Fault Tolerance and Reliability, 내구성을 지닌다.
Kafka Components
Topics
특정 이름이나 분류를 가지는 메시지 스트림을 Topic이라 일컫는다. Kafka에서 데이터는 Topic 내에 저장되며, Producer는 데이터를 topic에 쓰는 역할, Consumer는 데이터를 topic에서 읽어오는 역할을 한다.

Partitions
각 Topic은 여러개의 partition으로 나뉘어 관리되며, 갯수를 정할 수 있다.

여러개로 나뉘어진 Partition 구조를 통해 특정 topic을 여러 consumer가 병렬적으로 데이터를 읽어들일 수 있다. topic을 생성할 때 partition의 갯수를 설정할 수 있지만, 필요에 따라 순차적인 확장이 가능하다.
하나의 topic에 배정된 partition들은 Kafka 클러스터 전반에 분산되어 있으며, 특정 partition을 가지고 있는 서버가 partition 데이터와 다른 서버에서의 partition 요청을 관리한다.
Producer가 생성하는 메시지는 key를 가진 채 broker에게 전송되며, 이 key는 메시지가 저장될 partition을 결정하는 데 사용될 수 있다. 만약 key를 지정하지 않는다면, round-robin 하게 partition에 순차적으로 저장된다.
Partition Offset
Partition 내에 저장된 메시지 등 Record의 위치를 알기 위해, 각각의 Record는 offset을 가진다. 하나의 partition에서 offset은 unique하며, 오래된 Record일 수록 낮은 offset 값을 가진다.
Replicas
하나의 topic의 partition들은 Kafka 클러스터 전반에 걸쳐 publish 되는 동시에 복제본도 생성되는데, 이를 Replica라 한다. 일종의 partition 백업 개념으로, 계획된 shutdown이나 event of failure 시 데이터의 손실이 없도록 하기 위해 사용된다.
Brokers
Kafka 클러스터는 broker라 불리는 하나 이상의 서버 위에서 작동한다. Kafka broker는 여러개의 topic을 가지는 컨테이너의 역할을 한다.

unique한 ID를 통해 borker를 식별할 수 있어, 하나의 broker과 연결하는 동시에 Kafka 클러스터에 있는 모든 broker와 연결할 수 있다. 때문에 둘 이상의 broker를 가진 클러스터 환경에서, 각 broker들은 특정 topic과 관련 된 데이터의 전체를 가질 필요가 없다.
Consumers and Consumer Groups
Consumer는 Kafka 클러스터에서 데이터를 읽어들이는 역할을 한다. consumer들은 데이터를 읽어들일 준비가 되었을 때 broker에서 메시지를 Pull하며, 같은 topic에서 데이터를 읽어들이는 consumer들의 집합을 consumer group이라 한다.
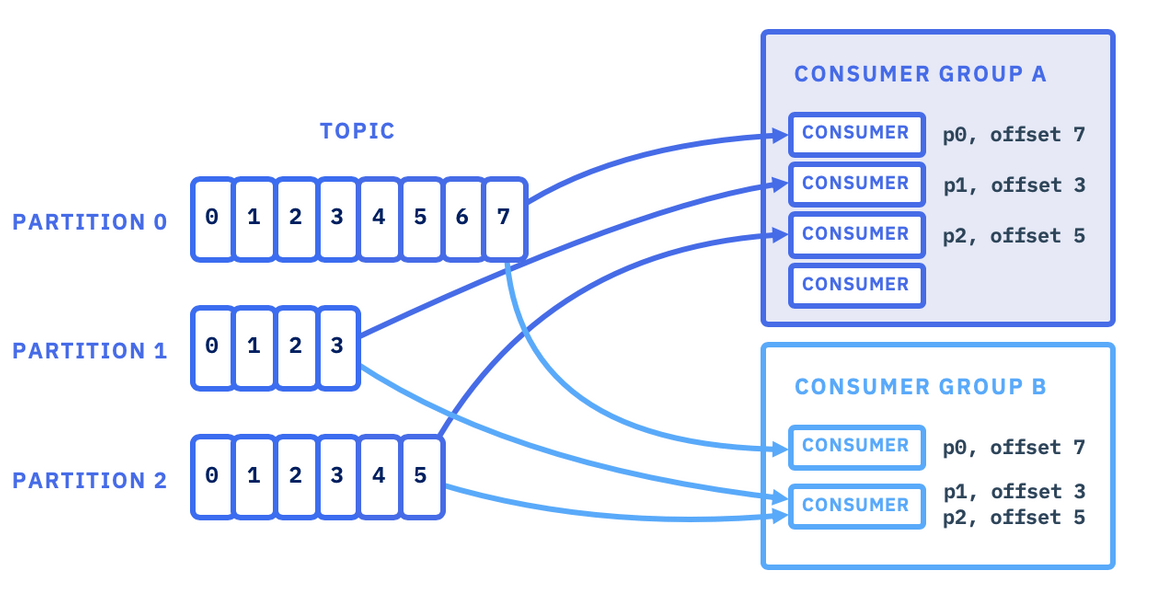
Producers
Producer는 하나 이상의 topic에 메시지를 씀으로 kafka 클러스터에 데이터를 전달하는 역할을 한다.

Producer가 언제든 메시지를 publish하면, broker는 메시지를 받고 특정 partition에 넣는다. 어떠한 partition에 메시지를 publish할 것인지는 Producer가 선택할 수 있다.
Leader and Follower
Kafka 클러스터 내의 모든 partition들은 특정 partition의 Leader 역할을 하는 서버를 가지고 있는데, Leader는 해당 partition의 읽기 쓰기 작업 수행에 책임을 진다. 각 partition은 0개 이상의 follower를 가지는데, follower는 leader의 데이터를 복제할 의무를 진다. leader의 failure시, follower 중 하나가 leader의 역할을 위임받는다.

Kafka Architecture

Push-based Producer
Producer는 지정된 partition의 leader 역할을 하는 broker에게 데이터를 직접 전달한다.
producer가 leader broker를 찾는 과정을 돕기 위해, Kafka 클러스터의 노드들-prodecer의 요청을 받은 leader가 아닌 broker들-은 어떤 노드가 작동중이고, partition들의 리더 상태를 알려준다. 이 작업은 partition key를 통해 각자에 맞는 partition으로 연결되거나, key 없이 진행될 수 있다.

Producer는 record batches라는 batch의 형태로 메시지를 전달하는데, 메모리 상의 batch에 특정 용량만큼 축적한 다음 전송하거나 특정 시간동안 batch를 쌓은 후 전송한다.
Broker의 작동방식
Kafka 클러스터는 load balancing을 위해 수많은 노드로 이루어져 있고, broker가 각 노드를 이룬다.
broker의 상태는 Zookeeper에 의해 관리되는데, 노드가 일정 주기로 Zookeeper에게 전송하는 Heartbeat 메시지를 통해 작동을 알린다.
만약 follower가 작동을 멈추거나 leader와의 연결이 끊기면, 해당 leader의 In-Sync Replicas(ISRs) 목록에서 제외된다.
만약 leader가 작동을 멈추면, 새로운 leader가 Zookeeper의 election 과정을 통해 새로 선출된다.
Pull-based Comsumer
consumer는 broker에게 데이터를 읽어오고 싶은 partition을 요청하여 메시지를 pulling 한다. consumer는 자신이 읽어올 데이터의 offset을 함께 요청함으로써 broker로부터 offset 지점부터의 메시지를 읽어들이게 된다.
consumer가 offset을 지정할 수 있기 떄문에, 필요하다면 같은 메시지를 재요청할 수 있다. record들은 retention period라 불리는 일정 기간동안 log 형태로 남아있을 수 있으며, consumer는 데이터가 log에 남아있을 동안 데이터를 다시 읽어들일 수 있다.

consumer는 pull-based 접근을 하기 때문에, broker가 데이터를 받은 즉시 consumer에게 전송되지 않을 수 있다. 이 시스템은 consumer가 과도한 부담을 덜 수 있게 해주고, 대용량 batching 또한 수행할 수 있게 해준다.
End to End Batch Compression
대용량 데이터를 다루는 만큼, Kafka는 메시지를 압축하여 관리한다. 여러개의 메시지를 묶어 압축하는것이 효율적이기 떄문에, Producer단에서 batch 단위(defaulkt 16KB)의 압축을 진행하는 Kafka는 효율적인 batching format을 지원한다.
broker에 저장되어있는 메시지들은 consumer에 의해 추출될때 까지 batch단위로 압축되어 log 형태로 남는다.

Kafka 설치
tgz 압축을 풀고 환경변수 설벙만 해주면 끝이지만, server.properties 내 Broker ID를 각 서버마다 다르게 설정해주어야 한다.
#Dockerfile
RUN mkdir /opt/kafka && \\
cd /opt/kafka && \\
wget <https://archive.apache.org/dist/kafka/2.7.0/kafka_2.12-2.7.0.tgz> &&\\
tar xvfz kafka_2.12-2.7.0.tgz && \\
ln -s /opt/kafka/kafka_2.12-2.7.0.tgz /opt/kafka/current
ENV KAFKA_HOME=/opt/airflow/current
ENV PATH=$PATH:$KAFKA_HOME/bin
COPY server.properties /opt/kafka/current/config#server.properties
############################# Server Basics #############################
# Broker의 ID로 Cluster내 Broker를 구분하기 위해 사용(Unique 값)
broker.id=1
#master01: 1
#master02: 2
#slave01: 3
############################# Socket Server Settings #############################
# Broker가 사용하는 호스트와 포트를 지정, 형식은 PLAINTEXT://your.host.name:port 을 사용
listeners=PLAINTEXT://:9092
# Producer와 Consumer가 접근할 호스트와 포트를 지정, 기본값은 listeners를 사용
#advertised.listeners=PLAINTEXT://localhost:9094
# 네트워크 요청을 처리하는 Thread의 개수, 기본값 3
num.network.threads=3
# I/O가 생길때 마다 생성되는 Thread의 개수, 기본값 8
num.io.threads=4
# socket 서버가 사용하는 송수신 버퍼 (SO_SNDBUF, SO_RCVBUF) 사이즈, 기본값 102400
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
# 서버가 받을 수 있는 최대 요청 사이즈이며, 서버 메모리가 고갈 되는 것 방지
# JAVA의 Heap 보다 작게 설정해야 함, 기본값 104857600
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 로그 파일을 저장할 디렉터리의 쉼표로 구분할 수 있음
log.dirs=/opt/kafka/current/logs
# 토픽당 파티션의 수를 의미,
# 입력한 수만큼 병렬처리 가능, 데이터 파일도 그만큼 늘어남
num.partitions=1
# 시작 시 log 복구 및 종료 시 flushing에 사용할 데이터 directory당 Thread 개수
# 이 값은 RAID 배열에 데이터 directory에 대해 증가하도록 권장 됨
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# 내부 Topic인 "_consumer_offsets", "_transaction_state"에 대한 replication factor
# 개발환경 : 1, 운영할 경우 가용성 보장을 위해 1 이상 권장(3 정도)
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
############################# Log Retention Policy #############################
# 세그먼트 파일의 삭제 주기, 기본값 hours, 168시간(7일)
# 옵션 [ bytes, ms, minutes, hours ]
log.retention.hours=168
# 토픽별로 수집한 데이터를 보관하는 파일
# 세그먼트 파일의 최대 크기, 기본값 1GB
# 세그먼트 파일의 용량이 차면 새로운 파일을 생성
log.segment.bytes=1073741824
# 세그먼트 파일의 삭제 여부를 체크하는 주기, 기본값 5분(보존 정책)
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# 주키퍼의 접속 정보
# 쉼표(,)로 많은 연결 서버 포트 설정 가능
# 모든 kafka znode의 Root directory
zookeeper.connect=172.16.238.2:2181,172.16.238.3:2181,172.16.238.4:2181
# 주키퍼 접속 시도 제한시간(time out)
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
# GroupCoordinator 설정 - 컨슈머 rebalance를 지연시키는 시간
# 개발환경 : 테스트 편리를 위해 0으로 정의
# 운영환경 : 3초의 기본값을 설정하는게 좋음
group.initial.rebalance.delay.ms=3
Kafka를 설치 한 각 서버에서 먼저 Zookeeper를 먼저 실행시킨 후, Kafka 서버를 실행한다.
[master01 ~]$ kafka-server-start.sh -daemon /opt/kafka/current/config/server.properties
[master02 ~]$ kafka-server-start.sh -daemon /opt/kafka/current/config/server.properties
[slave01 ~]$ kafka-server-start.sh -daemon /opt/kafka/current/config/server.properties
topic을 생성한 다음, describe 옵션을 통해 확인할 수 있다. zkCli에서도 broker와 topic 확인이 가능하다.
[master01 ~]$ kafka-topics.sh --create --zookeeper 172.16.238.2:2181, 172.16.238.3:2181, 172.16.238.4:2181 --replication-factor 3 --partitions 3 --topic test
[master01 ~]$ kafka-topics.sh --describe --zookeeper 172.16.238.2:2181, 172.16.238.3:2181, 172.16.238.4:2181 --topic test
Topic: test PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: Twitter-test Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 1,2
Topic: Twitter-test Partition: 1 Leader: 1 Replicas: 3,1,2 Isr: 1,2
Topic: Twitter-test Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 1,2
[master01 ~]$ zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 0] ls /brokers/topics
[test, __consumer_offsets, __transaction_state]
간단한 console-producer와 console-consumer를 실행하여 테스트할 수 있다. 두개의 터미널을 띄우고 producer 콘솔 입력을 통해 consumer 콘솔 출력을 확인할 수 있다.
[master02 ]$ kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
[slave01]$ kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
제작중인 Twitter API의 SampledStream을 이용한 Kafka producer이다.
https://github.com/gegurakzi/KafkaProducer
GitHub - gegurakzi/KafkaProducer
Contribute to gegurakzi/KafkaProducer development by creating an account on GitHub.
github.com
'데이터 엔지니어링 > 빅데이터' 카테고리의 다른 글
| [1. 차원 모델링] 1-1. 차원 모델 설계의 4단계 (0) | 2024.04.22 |
|---|---|
| Hadoop YARN (0) | 2022.11.30 |
| Apache Airflow (0) | 2022.06.01 |
| Spark Streaming (0) | 2022.05.27 |
| Spark RDD (0) | 2022.05.24 |